Python으로 웹스크래핑하기(Web Scraping with Python)
World Wide Web(WWW)
- URL로 구분된 하이퍼텍스트(Hypertext)를 공유하는 정보의 공간
- text: 텍스트는 이렇게 생겼구요
- Hypertext: 하이퍼텍스트는 이렇게 생겼답니다.
HTTP(HyperText Transfer Protocol)
- 하이퍼텍스트를 주고 받기 위한 서로간의 약속

HTML (HyperText Markup Language)
- 웹 문서에 구조를 만드는 언어
- css 를 사용하여 스타일을 입히고, Javascript를 사오요하여 동적인 움직임을 추가할 수 있음.
- 텍스트로된 HTML + CSS + Javascript가 브라우저를 거쳐 우리가 보는 이쁘게 렌더링된 화면으로 전환됨.
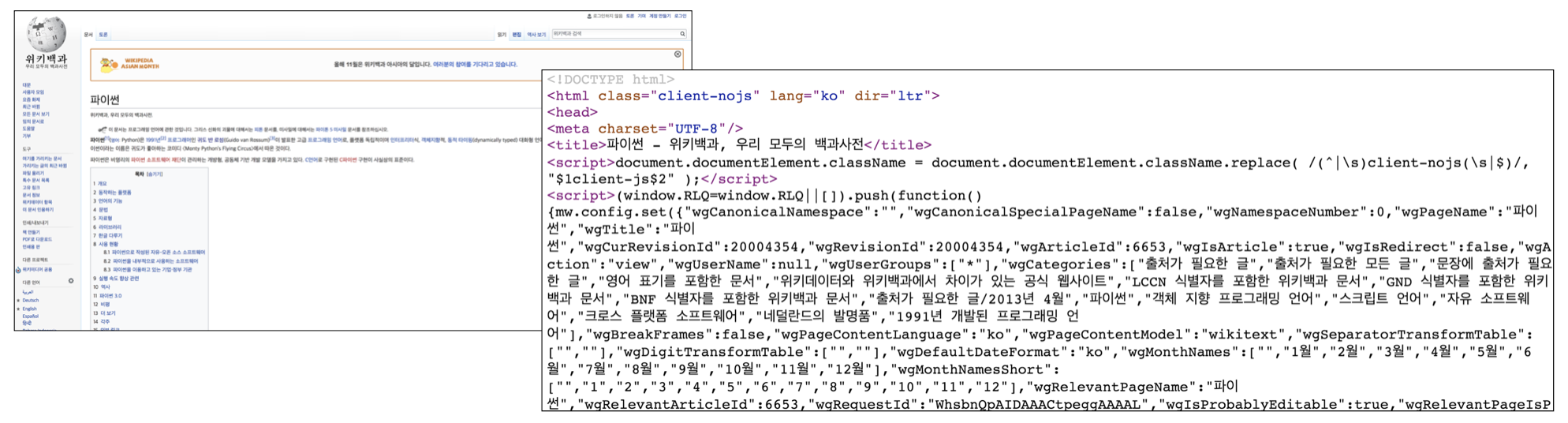
HTML tag
<TagName> Content </TagName>
- 제목, 본문, 리스트, 이미지 첨부 등 문서 구조를 표현하는 기능을 합니다.
- TagName은 규격화되어 있습니다.
- 보통 여는태그와 닫는태그로 되어있습니다.
HTML Class
<TagName1 class='myClass'> first Content </TagName1>
<TagName2 class='myClass'> second Content </TagName2>
- 여러 Tag혹은 하나의 Tag를 특정 Class이름으로 그룹화할수 있습니다.
HTML ID
<TagName id='myid'> Content </TagName>
특정 Tag에 id를 부여합니다.
id이름은 전체 문서에서 유일해야합니다.
기본 HTML 구조
<!doctype html>
<html>
<head>
<title>Hello HTML</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>
Web Crawling
- 웹을 자동으로 탐색하며 구조화된 정보(xml, html 등)을 수집하는 일
Web Scraping
- 웹에 게시된 문서를 수집하는 행위
Requirements
- Python으로 웹 스크래핑을 하기 위해 필요한 라이브러리를 알아봅시다.
requests
- Python에서 웹 서버에 요청을 보내고 응답을 받는 행위와 관련된 라이브러리
pip install requests
beautifulsoup
- 요청을 통해 받은 응답을 분석하여 원하는 값을 얻을 수 있도록 도와주는 라이브러리
pip install beautifulsoup4
BeautifulSoup 기본 사용법
>>> from bs4 import BeautifulSoup as bs
>>> result = bs(response.text, 'html.parser')
>>> result.find('태그이름')
# 해당 태그를 가진 첫번째 요소를 반환
>>> result.findAll('태그이름')
# 해당 태그를 가진 모든 요소를 list로 반환
>>> result.find('태그이름', {'class': 'className'})
# 해당 태그중 해당 클래스이름을 가진 첫번째 요소를 반환, id도 사용가능, class와 id동시 사용 가능
>>> result.find('태그이름').text
# 해당 태그를 가진 첫번째 요소에 태그안에 텍스트를 반환
추가 과제 1.
박스오피스 정보 긁어내기
import requests # 요청을 보내기 위한 requests
from bs4 import BeautifulSoup # 응답을 분석하기 위한 BeautifulSoup
# url에 요청을 보낼 주소를 지정하고 requests로 요청을 보내 그 응답을 response에 저장합니다.
url = "https://www.rottentomatoes.com/"
response = requests.get(url)
# 응답 결과로 받은 html을 BeautifulSoup으로 분석합니다.
html = response.text
soup = BeautifulSoup(html, "html.parser")
# html 전체 중 id가 일치하는 table 태그를 선택합니다.
table = soup.find("table", attrs={"id":"Top-Box-Office"})
# table에서 모든 tr태그를 찾아냅니다.
all_tr = table.find_all("tr")
# tr태그 리스트 요소를 반복시키면서 td > span 의 텍스트를 추출해 score와 movie_name을 바로 출력합니다.
for tr in all_tr:
all_td = tr.find_all("td")
score = all_td[0].find("span", attrs={"class":"tMeterScore"}).text
movie_name = all_td[1].a.text
print(score, movie_name)
추가 과제 2.
생활환경안전정보시스템 초록누리 유해화학 물질정보 페이지의 첫페이지에 보이는 화학물질을 크롤링 해보세요!
Sample output
[['번호', 'CAS번호', '영문명', '국문명'],
['52', '1333-82-0', 'Chromic anhydride', '무수 크롬산'],
['51', '1336-21-6', 'Ammonium hydroxide', '암모늄수산화물'],
['50', '110-80-5', 'Ethylene glycol monoethyl ether', '에틸렌 글리콜 모노에틸 에테르'],
['49', '111-30-8', 'Glutaraldehyde', '글루타르알데히드'],
['48', '1341-49-7', 'Ammonium hydrogendifluoride', '이플루오르화암모늄'],
['47', '64-67-5', 'Diethylsulfate', '다이에틸 황산염'],
['46', '108-88-3', 'Toluene', '톨루엔'],
['45', '108-91-8', 'Cyclohexylamine', '사이클로헥실아민'],
['44', '108-95-2', 'Phenol ; Hydroxybenzene', '페놀'],
['43', '109-86-4', '2-Methoxyethanol', '2-메톡시에탄올']]
과제를 성공하셨나요?
코딩 101 참가자 분들 중에서, 과제에 성공하신 후 메일로 보내주세요.
선착순으로 [패스트캠퍼스 스쿨 할인권] 을 드립니다!